本文主要是翻译sebastien-han的三篇博客:ceph-io-patterns-the-good 、ceph-io-patterns-the-bad、ceph-io-patterns-the-ugly 欢迎加入 翻译组
一切都是为了性能。基准测试是非常复杂的,得到的测试结果总是难以预测、分析和解释。有时你得到了测试数据,但你不知道它们的意思,也不知道这个结果到底是好呢还是坏呢?好又好在哪里,不好又哪里是瓶颈。在这篇文章中,我将尽力详细的讲解以帮助你理解内部Ceph是如何工作的。
1. The good
1.1 确定的对象位置
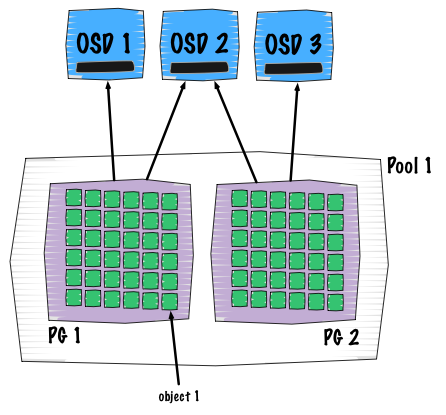
关于这一点我相信大家已经熟知了,但是在这里我还是要再次解释一下。Ceph用以确定对象位置的方法是独一无二的:
客户端写入顺序(位置和从属关系见上图):
- => 一个确定的资源池(包含对象的逻辑概念)
- => 这个资源池包含有placement groups (可以看做是资源池的分片)
- => 这个PG 包含对象
- => 这些对象只属于一个placement group
上面几个过程都是通过计算实现的, 这使得整个过程具备可重复性和确定性。所以没有哈希表查找,只有公式和计算。这个公式就是我们通常所说的RADOS算法,它决定了对象在集群内的具体位置。
1.2 整合: 集群层面
一旦有数据写入Ceph,所有对象在整个集群的节点和磁盘内均匀分布。
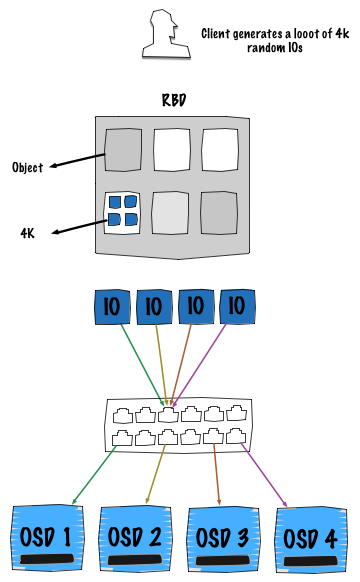
上图阐述了RBD块设备的一个常用使用场景:映射到一个物理机或者一个虚拟机。这两种情况对于存储集群而言是相同的行为,因而无需单独讨论。在这种场景下,客户端产生大量的4K随机操作。显然,在此图中OSD代表一个磁盘。
正如在前一节中阐述的那样,客户端每次执行一个IO操作都需要计算位置。也多亏了RADOS算法,所有的4K IOs能够充分利用整个集群的网络、磁盘和带宽来将其均匀分布到整个集群。
注意: 这里的瓶颈可能是交换机的背板带宽,因此需要确保它能够很好的支撑每一个链路的最高速度。
1.3 整合: OSD层面
一旦有IO到达OSD,不管原来的模式是什么,此时都是连续的。
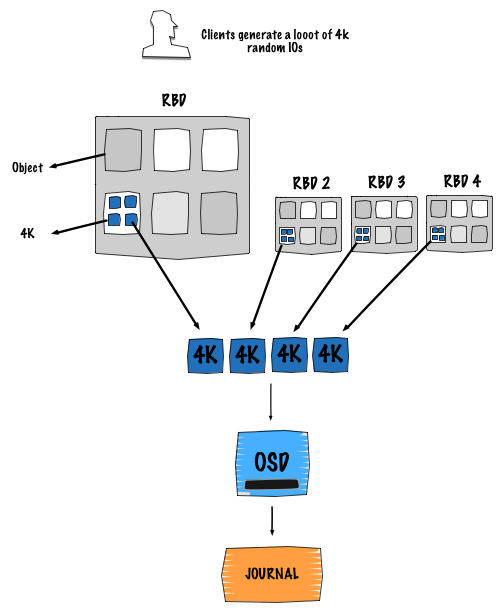
上图描述了这样一种场景:不同客户端计算对象位置的时候最终落到了同一个OSD上面。这是相当普遍的一种场景,而且这是一直在发生的事。不同客户端计算它们的对象的位置,最终会落到一个特定的OSD上面。
这样做的好处是进入到日志的写请求都被序列化了。基本上,客户端的写都是排队进入日志,再等待被flush到后端存储,就像进入到FIFO。
注意: 这样做的真正好处是能够使用专门的磁盘来存储日志,一般是指SSD。
确认有效: 主副本OSD在将数据写入日志的同时也将它们发送给其他副本。
2. The bad
2.1 日志化
每当有IO请求到达OSD的时候,它都会需要两次写操作。
这个表述只关注了日志层面,详情见下图:
2.1.1 单次写
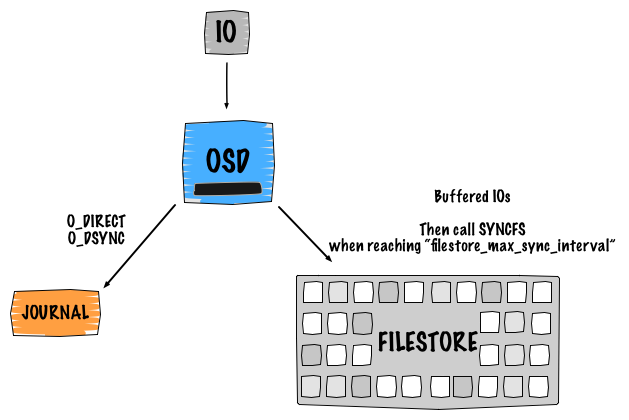
Ceph是软件定义存储,这意味着数据的副本和可用性都是由软件智能实现。我认为理解Ceph内部是如何工作的相当重要(默认的逻辑架构)。本文的重点是向你们展示当执行一个写操作的时候底层究竟发生了什么。那么,我们举一个副本数是2的单个对象写的实例来详细阐述。这个写会导致4个IO:
- 客户端发送请求到主副本OSD
- 第一个IO写入该OSD的日志中
- 日志使用libaio,使用
O_DIRECT和O_DSYNC来进行写操作。使用writev()来处理这个写操作 - 第二个IO是使用
buffered_io将数据写入到后端文件系统中,使用writev()处理写操作 - filestore在达到
filestore_max_sync_interval设定的时间间隔后,调用syncfs并删除日志中对应的条目,并等待syncfs结束再释放锁。
采用同样的操作将数据复制到第二副本OSD。
2.1.2. 关于日志
在前面一幅图中,我提到了日志,但是它到底是干什么的呢?其中几个主要的操作如下:
- 保证数据和操作的一致性。正如传统的文件系统日志一样,因此它可以在发生错误的时候进行回滚
- 提供原子操作。它保持对已经提交和即将提交的操作的跟踪。
- 在日志中的写是连续的
- 工作模式是FIFO
Ceph OSD守护进程在合适的时候停止写操作,然后同步日志到文件系统,同时允许Ceph OSD守护进程从日志中删除已经写入后端存储的数据以便实现空间重复利用。
上面的表述对于OSD的文件系统是Btrfs或ZFS的情况是不适用的。一般而言,我们建议OSD使用XFS或ext4做文件系统,它们的日志模式是writeahead:先写日志再写到后端文件系统。这跟COW(Copy On Write)文件系统是一个不同的方法,因为它使用的是writeparallel模式即同时写日志和后端文件系统。
2.1.3. 设计的副作用(Design penalty)
显然,你已经注意到了,在writeahead模式下使用日志在写对象的时候会有比较大的性能损耗这一副作用。因为我们写了两次,对于日志跟后端文件系统在同一个磁盘的情况,会导致如下结果:
Device: wMB/s
sdb1 - journal 50.11
sdb2 - osd_data 40.25
传统的企业级SATA盘在顺序写IO模式下可以提供大约110MB/S的速度。是的,基本上说我们将其分成两个IOs。
为了避免(或隐藏)这种影响,实现日志有以下几种方法。
通常,Ceph日志是文件系统上的一个文件(位置在 /var/lib/ceph/osd/<osd-id>/journal )。首先因为文件系统的开销因而这种方式这是非常低效的,其次我们无法确定的知道日志在物理磁盘上的确切位置。(文件和块之间的相关性)。
实现它的另一种方法是使用OSD数据磁盘的起始裸分区。基本上,你只需要使用最开始的一部分扇区新建一个小的分区来存储日志。由于我们使用的是磁盘的最开始的部分,我们确信这是磁盘上最快的部分。磁盘的外部总是更快的,当磁头越接近中心,性能开始下降(这是一个众所周知的问题)。如果你不想为了日志单独使用一个磁盘的话,这是最好的方法。
如果你需要更高的性能,可以使用一个独立的磁盘。不幸的是,因为有大量并发日志写而导致磁盘需要花费大量时间进行寻道。
最后,实现日志的最好方法是使用一个单独的SSD盘。多亏了它,你能够使用SSD的诸多有点:无需寻道,快速顺序写和快速访问时间。
2.2. 文件系统碎片
存储在Ceph中的每个对象在后端文件系统上实际是以文件的形式存在。默认情况下,这些对象存放在 /var/lib/ceph/osd/<osd.id>/current/<pg.id>/ 下。由于Ceph作为动态集群而天生具备的分布式特性,Ceph总是针对对象(此处理解为文件)在执行写和更新操作。这样的负载对于传统文件系统而言是很重的,同时如此密集的操作可能导致大量的碎片。很明显,这会导致时延加剧,现而今,文件系统已经具备了诸如精简制备等机制能够有效地控制文件系统碎片。如果你使用RBD,它能够很好的作为虚拟机的块设备和机器的裸设备工作,对象块大小是4MB(默认开启条带)。然而,Ceph集群中的每一个镜像都可以有自己的条带和方法。
注意:文件系统碎片很少会被考虑,因为文件系统老化很难模拟。
在Ceph环境中,我们都公开承认:随着时间的推移性能会慢慢下降。对于使用一年的老集群系统而言,可以使用下面的方法应对:
$ sudo xfs_db -c frag -r /dev/sdd
actual 196334, ideal 122582, fragmentation factor 37.56%
幸运的是,Ceph核心开发人员最近发起了一个针对这个问题的项目。这个新功能叫做RADOS IO hints。它将执行类似 fadvise(2) 的操作。 fadvise(2) 是一个系统调用,可以用来提示Linux如何缓存文件。这样,内核就可以选择合适的read-ahead和缓存技术来访问到相应的文件。对于更详细的实现方式,请看邮件列表讨论。
2.3. 没有并行读
目前,Ceph不提供任何并行读功能,这意味着Ceph总是从主副本OSD提供读服务。因为我们通常有2个或更多的副本,因此读性能应该可以大大改善。我记得在Ceph邮件列表中有过讨论,但是现在找不到任何资料了。但是我相信它已经是Ceph的一部分开发人员的待办事项。
2.4. 深度清洗消耗IOs
清洗是对对象的一种fsck。它在PG层级检查对象一致性,并且比较对象的主副本和其他副本的版本。
目前有两种清洗类型:
- 轻度清洗(每天)检查对象大小和属性
- 深度清洗(每周)读取数据并使用校验值来确保数据一致性
目前很多用户反馈,深度清洗会对集群产生重大影响。应对这个IO开销的方法很有限,你也可以禁用它,但是你需要使用你自己的方式来实现清洗并使用合适的参数控制它的行为。
Ceph希望尽可能的保证事务和数据的安全。显然,这是要付出代价的,这就是性能。然而,我们看到已经有一些技术来解决Ceph这种设计带来的副作用。
3. The ugly
在此之前,我想稍微扯点别的。这里我想公开阐述的问题不仅仅是Ceph存在,其他的分布式存储系统也存在。所以,请牢记一点,下面要讲述的问题不仅仅是Ceph才有。
3.1. RBD的IO模式
一个IO进入到Ceph后会有两次写,第二次写性能更糟:
原理:
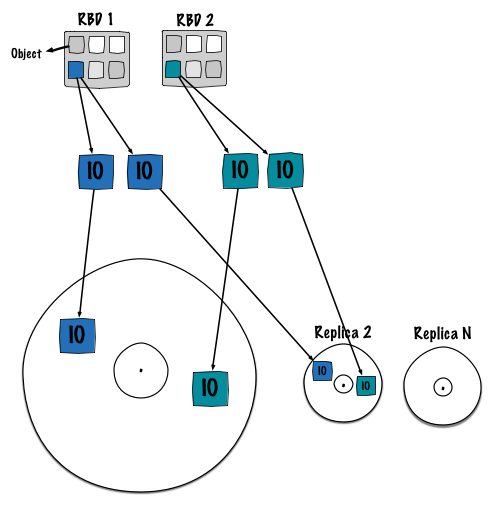
在我最后一次基准测试期间,我们有一个类似的假设,然而我们没有得到机会来证实这个事实。幸运的是英特尔的研究人员将这种假设证实为现实。这种现象很容易理解。基本上,由于其分布式特性以及Ceph的确定性存储对象。因此,对象(来自不同客户端)映射到相同的OSD磁盘。最终顺序流混合在一起。下面是Ceph的IO操作队列的一个实例:
- object1 points to pg1.1
- object2 points to pg1.2
- object3 points to pg1.3
- object4 points to pg1.4
- object5 points to pg1.5
OSD 1负责这5个PG。然而没人知道这5个目录在文件系统的哪里(/var/lib/ceph/osd/osd.1/current/pg1.{1,2,3,4,5})。如图所示,PG在块设备上有一个确定的位置(文件系统)。最后,磁盘消耗大部分的时间从一个轨道跳到另一个,因此整体性能下降了。
由于我讨厌复述,我将引导你们找到来自Intel的那篇详细解释这种现象的杰出博客。点击这里
3.2. 如果使用erasure coding情况会更糟
借用一下 Loic Dachary’s 的图片:
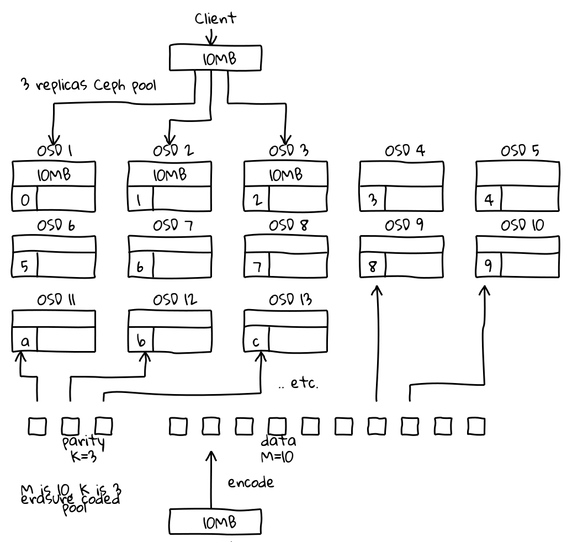
这只是一个假设。由于erasure code会给块再分块,因此前面的现象可能会被放大。如图所示,这里不是写3份对象,这里写13份对象:10 x 1M(分块)+ 3(奇偶校验)。我相信erasure code能够为你节省空间,但同时也会降低性能。
你必须亲自验证。
最后两个小节有一点偏离IO模式的主题,但是我相信它们很重要,值得认真考虑。
4. 内存位损坏(Memory bit corruption)
内存位损坏大多是因为从某一个位置上发生了移位。在分布式副本环境中比如Ceph,这可能导致大规模的数据损坏,因为损坏会在整个集群中扩散。如果发生了移位,一般是很难检测到的,因为客户端文件写入一个文件,而就在其进入Ceph集群的时候就直接损坏了。使用ECC内存针对这种问题的是一个通用的实践方案。
了解详情见 Wikipedia
5. 软件定义存储
Ceph是一种软件定义存储,这意味着你所有的IO的计算、存储和平衡都是在程序员写的软件程序的帮助下实现的。因此由于某种原因导致的软件故障可能摧毁你的所有数据。我们已经看到在Ceph中过去的一些特性或标志可能导致数据损坏,不幸的是,一旦你发现它已经太迟了。据我所知,这是有史以来最糟糕的场景但这里的概率是比较低的。