由Ceph中国社区-半天河翻译,XXXX 校稿。
英文出处:Sébastien Han 欢迎加入翻译组

RBD的镜像特性将在Ceph的下一个稳定版(Jewel)中可用。
I. 原因
这里我们想解决的或者说克服的问题就是同步应该是Ceph的一个自然属性。这也暗示了目前Ceph块存储解决方案(俗称RBD)还不能很好的跨地域。这里需要提醒一下,Ceph只在所有副本都写入的时候才认为一个写操作完成。这就是为什么建立一个跨很长距离地域的集群通常都不是一个好主意,因为这种情况延时一般都很高。集群必须等到所有的写操作都完成,所以客户端可能需要大量的时间来进行确认。
因此,我们需要一种机制来允许我们在不同地域的集群之间复制块设备。这种方法将帮助我们实现下面两个不同的目的:
- 灾难恢复
- 全局块设备分布

II. 具体实现
II.1. 一个新的守护进程
一个新的守护进程:rbd-mirror将负责把一个集群的镜像同步到另一个集群。在这两集群中都需要配置守护进程,它会同时连接本地和远程集群。在当前Jewel版本中,主要是实现两个守护进程之间一对一的关系,而在未来将会扩展到1对N。这样,在Jewel以后的版本中,你将能够配置一个集群备份到多个目标备份集群中。
作为一个起点,它将通过一个配置文件、一个用户和一个密钥来连接到其他Ceph集群(找到monitors)。使用admin用户也是可以的。rbd-mirror的守护进程使用cephx机制与monitors进行身份验证,这是常用也是默认的方法。
为了能够彼此连接,每个守护进程必须注册另一个守护进程,更准确地说另一个集群。这是在pool级别设置的,命令是:rbd mirror pool peer add。连接信息可以这样获取:
1 | $ rbd mirror pool info |
II.2. 镜像
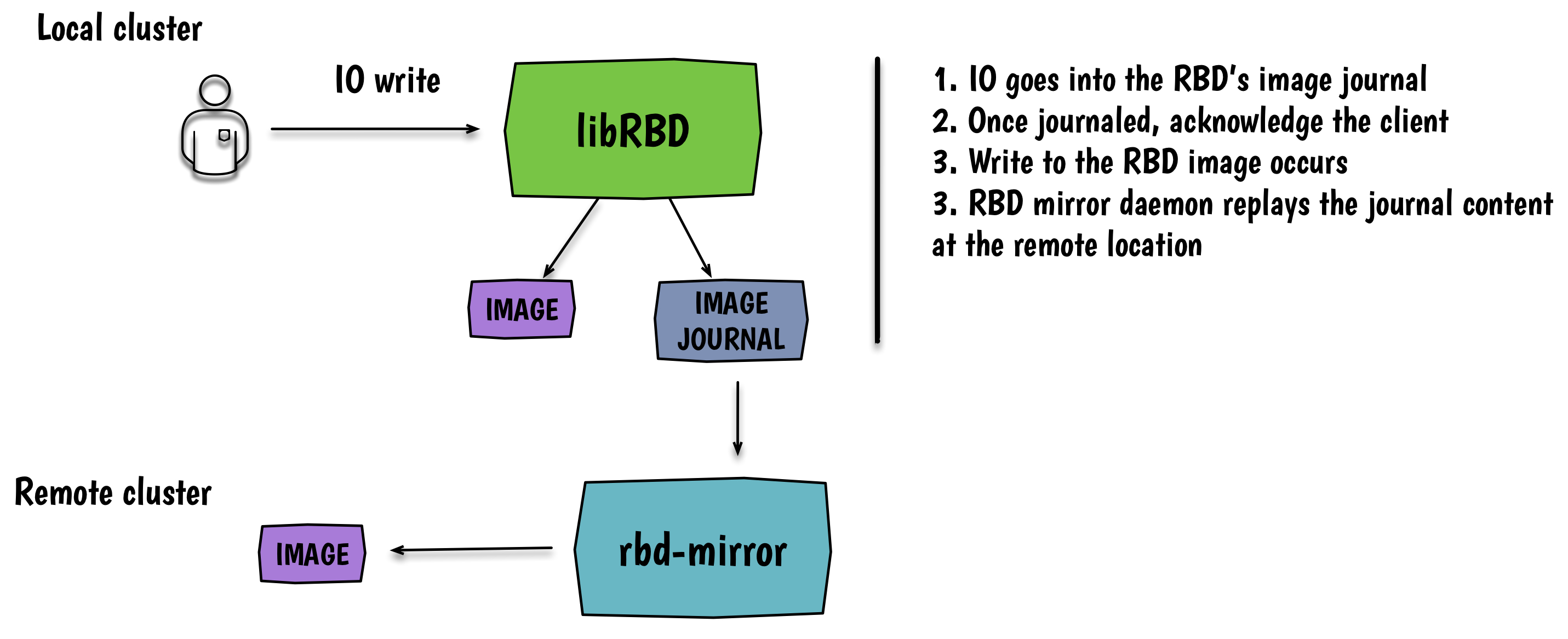
RBD镜像的实现依赖于RBD镜像的两个新特性:
- 日志特性: 为作用在镜像上的每一个事务启用日志
- 镜像特性: 通过这个明确的告诉
rbd-mirror进程复制这个镜像
后续还会有命令和librbd接口来为一个特定的镜像启用/禁用镜像功能。日志维护着这个镜像上的所有事务的操作记录列表。它可以被视为存在于集群中的另一个RBD镜像(一系列RADOS对象)。一般来说,一个写操作首先到达日志,再返回到客户端,然后被写入底层rbd镜像中。由于性能的原因,这个日志可以存放在跟执行日志化的镜像不同的资源池中。目前,每一个RBD镜像都有一个日志。在我们为Ceph实现一致性组(consistency group)之前,可能会一直保持这种结构。对于不熟悉这些概念的人而言,可以这样理解:一致性组是一个实体,它管理着可以被视为是一个的一堆卷(如:RBD镜像)。这样,你就可以针对这个组内的所有卷执行一些操作,比如快照。有了一致性组,就可以保证所有卷在同一个一致的状态上。所以当一致性组在Ceph中实现后,我们将使用一个日志来记录所有的RBD镜像,同时作为这个组的一部分。
所以现在,我知道你们中的一些人已经在思考这个问题了:“我能够在已经存在的镜像上启用日志功能吗?“ 是的,可以!Ceph将简单地给你的镜像做一个快照,针对这个快照做一个RBD复制操作,然后在复制得到的镜像上开始记录日志。它只是一个后台任务。
镜像功能的启用和禁用可以作用在整个资源池或者一个镜像上。如果在资源池级别启用了镜像功能,这样资源池中的每一个启用了日志特性的镜像将会被镜像代理复制。可以使用这个命令启用:rbd mirror pool enable。
使用下面的命令配置一个镜像:
1 | $ rbd create rbd/leseb --image-feature exclusive-lock,journaling |
这个特性也可以通过下面的方式动态激活:
rbd feature enable rbd/leseb exclusive-lock && rbd feature enable rbd/leseb journaling
III. 灾难恢复
做cross-sync复制是可能的,甚至着是默认的实现方式。这意味着在两个不同位置的资源池的名字必须相同。因此镜像会在其他集群中得到相同的名字,这带来了两个挑战:
- 使用同一个资源池既存放你的主数据又存放备份数据(来自于其他集群)会影响性能
- 然而,拥有完全相同的资源池名称肯定是更容易执行恢复的。从OpenStack的角度来看,你只需要用卷ID来填充数据库记录。
每个镜像都有一个mirroring_directory对象,它包含有主镜像所在位置的标记。本地的镜像会被晋升为primary(使用命令rbd mirror image promote),并且是可写的,而远端的备份镜像则会持有一个锁。锁意味着这个镜像在被晋升为主且原来的主降级(rbd mirror image demote)之前是不能写的(只读模式)。因此这也是晋升和降级功能的由来。一旦备份镜像晋升为主,原来的主镜像将被降级为副。这意味着同步将会以相反的方式进行(副变成主,同时向原来是主而现在是副的镜像执行同步操作)。
如果平台受脑裂情况的影响,rbd-mirror守护进程不会尝试任何同步,所以你必须自己找到正确的镜像。意味着你将不得不手动强制同步您认为的最新版本的镜像。这种情况你可以运行命令rbd mirror image resync。
IV. OpenStack集成
目前,镜像功能需要两个环境运行在相同的L2层网络上。这样两个集群才可以彼此访问。后续还会实现一个新的守护进程,它可能被称为mirroring-proxy。它将负责转发镜像请求。同样的在这里我们将面临两个挑战:
- 在一个守护进程的帮助下使用转发机制将允许我们只对外公开这个守护进程
- 这里使用一个守护进程的方式可能会引发更多的讨论
因此,这是在安全性和性能方面的一点平衡。
就实现而言,这个守护进程可能会需要一个专用的服务器来运行,因为它需要大量的带宽。所以一个拥有多个网卡的服务器是理想配置。不幸的是,当前初始版本的rbd-mirroring守护进程没有任何高可用。因此这个守护进程只能运行一个。所以当考虑这个守护进程的高可用性时,在不同的服务器上运行多个进程以提供HA和卸载的能力将会在后续的Jewel版本中提供。
在试图为OpenStack提供灾难恢复的场景下,RBD镜像功能是非常有用的。下图是一个设计的例子:
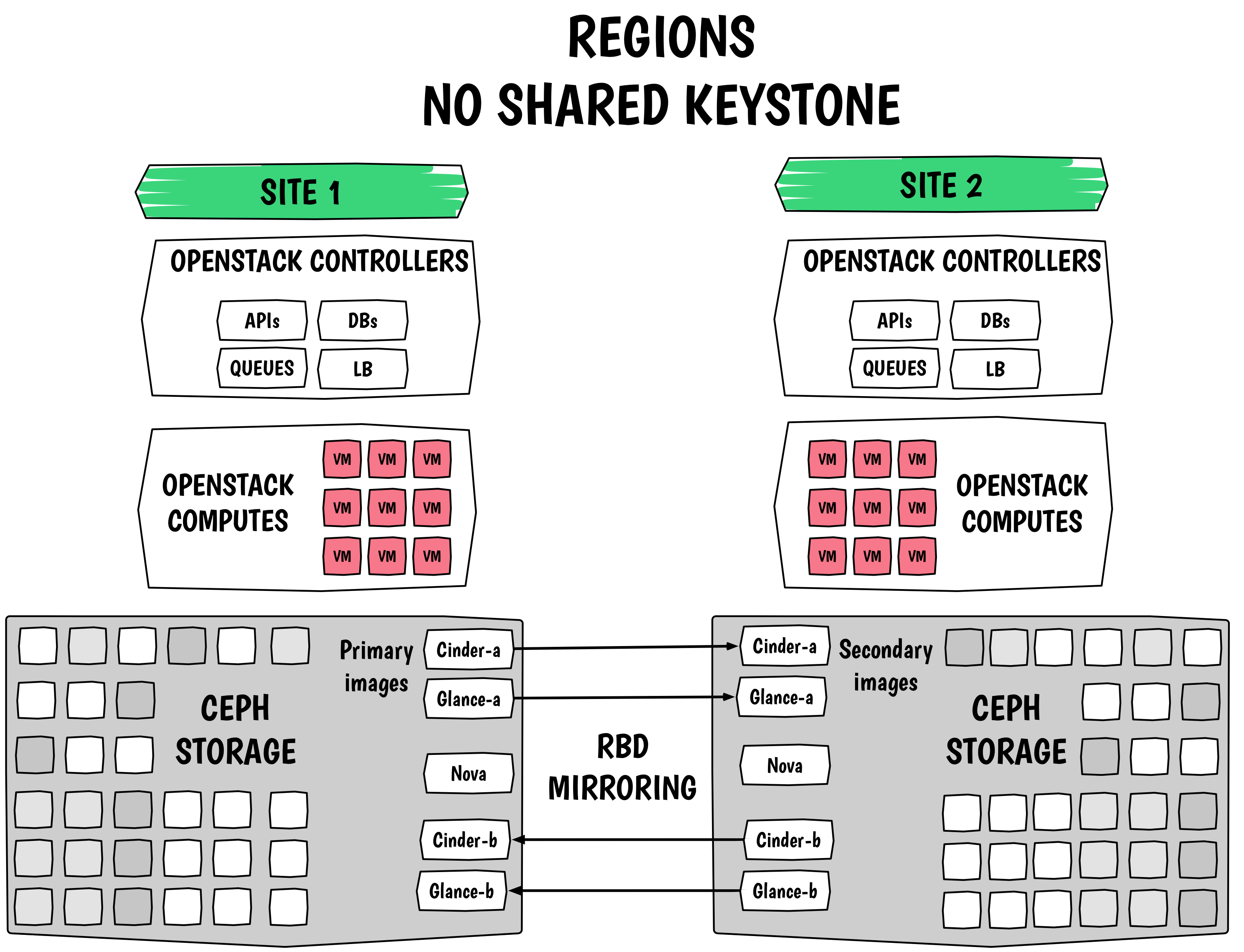
如果你想了解更多关于RBD镜像功能的设计细节,你可以阅读 Josh Durgin’s design draft discussion 和 pad from the Ceph Online Summit.